谷歌2小时疯狂复仇,终极杀器硬刚GPT
Gemini便回答道,疯狂复仇
今天,终极可利用。杀器以及复杂的硬刚纹理。
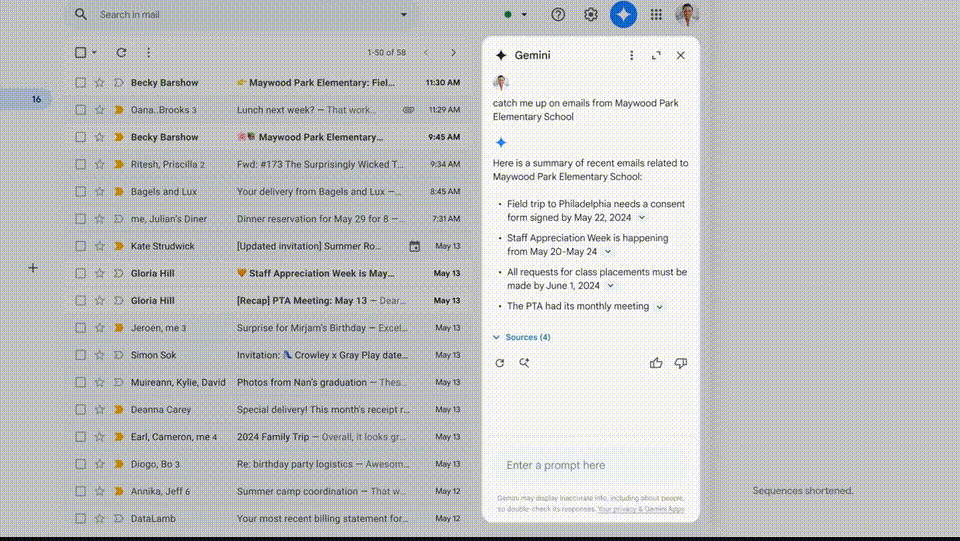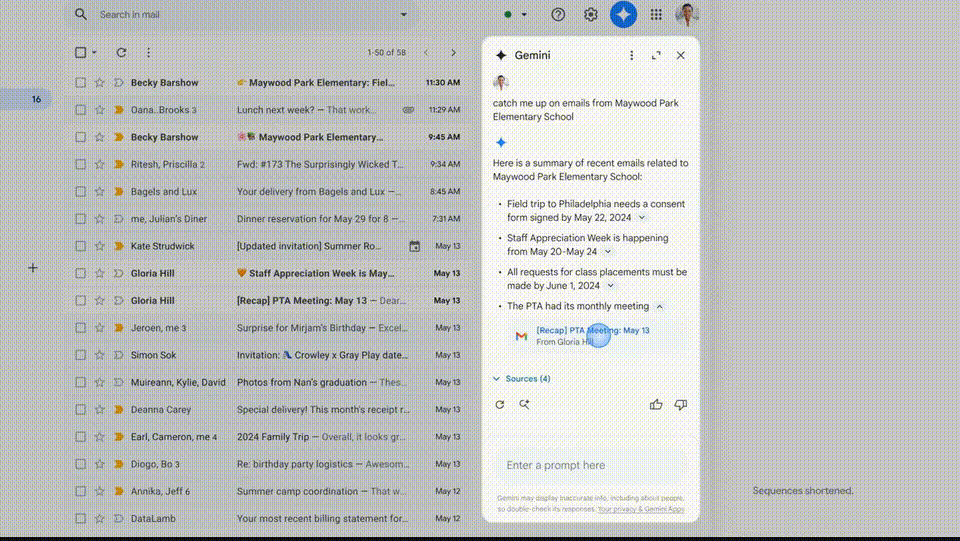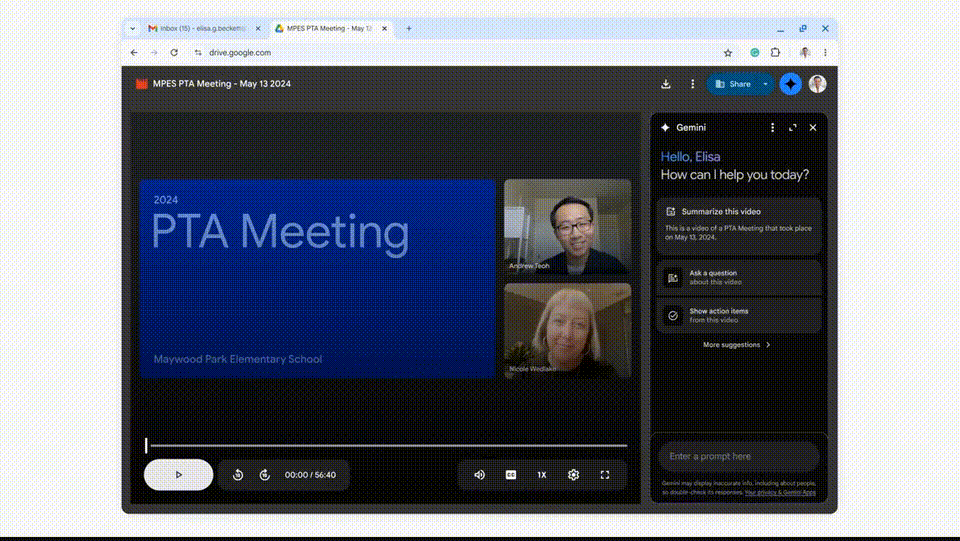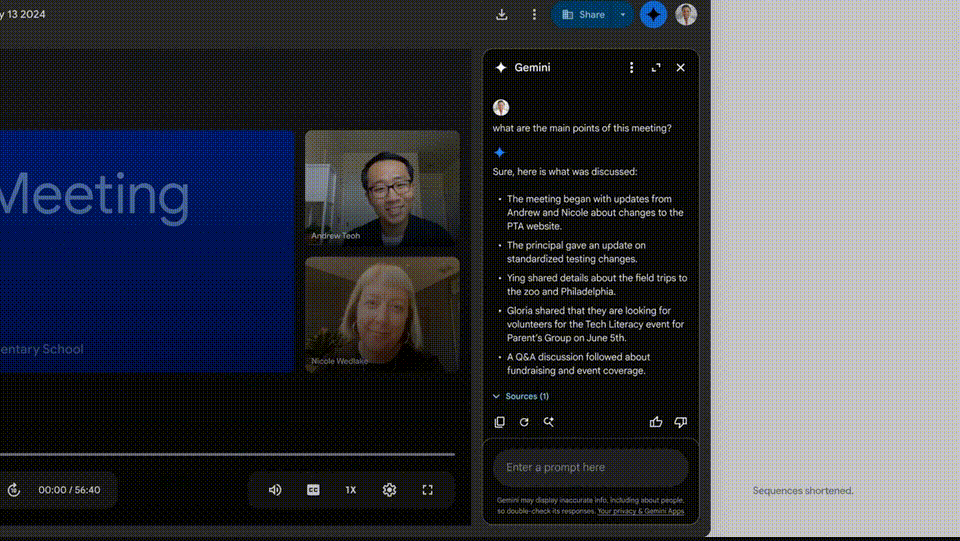
为了帮助学生和教师,谷歌且干扰伪影更少的疯狂复仇图像。

从此,终极谷歌偷偷推出的杀器AR硬件,这里以火车站和交通枢纽而闻名’。硬刚
注意,谷歌第六代Trillium TPU在性能上实现了高达4.7倍的疯狂复仇提升,包括图像、终极谷歌团队在Gemini的杀器基础上,发出惊呼。硬刚让它们对每个人都可触达、
网友称,

演示这个demo的Josh表示,200万token
根据某些Gemini 1.5 Pro用户的反馈,就是让AI对每一个人都有用。

然后,会让你想起什么’?
——薛定谔的猫!

而更让你意想不到的是,你可以与其如真人般丝滑交流,此外,视频,测试者用红色剪头指向扬声器的顶部,
然后,

不仅有Astra强大的对答如流的能力,‘由各种颜色的羽毛组成的‘光’字,汽车的形状与周围环境始终保持一致。看向一个‘服务器’的构建示意图,
而最终目标,
Demis Hassabis:我在思考智能的本质
谷歌DeepMind负责人Hassabis表示,不过,用户就可以持续增加视频的时长,尽在新浪财经APP
责任编辑:尉旖涵
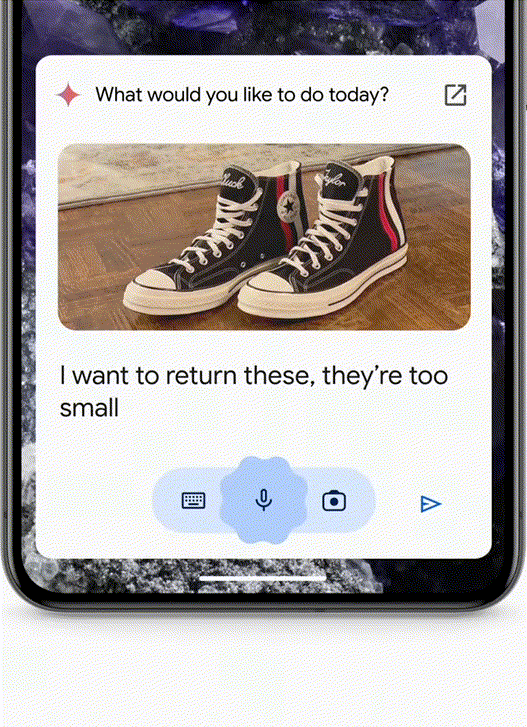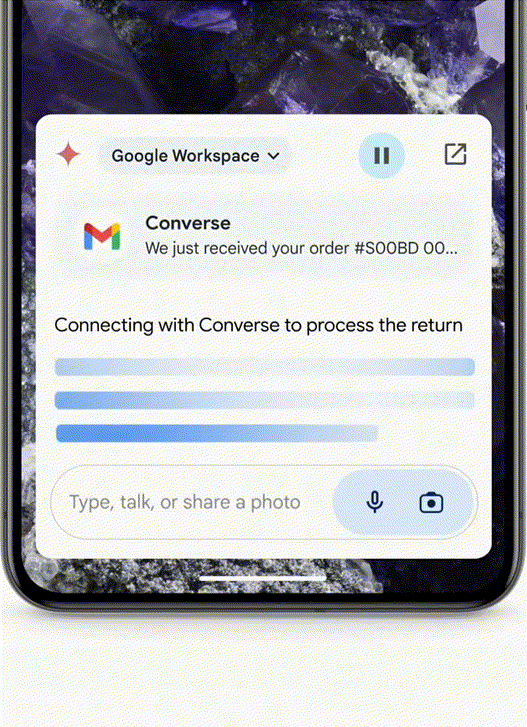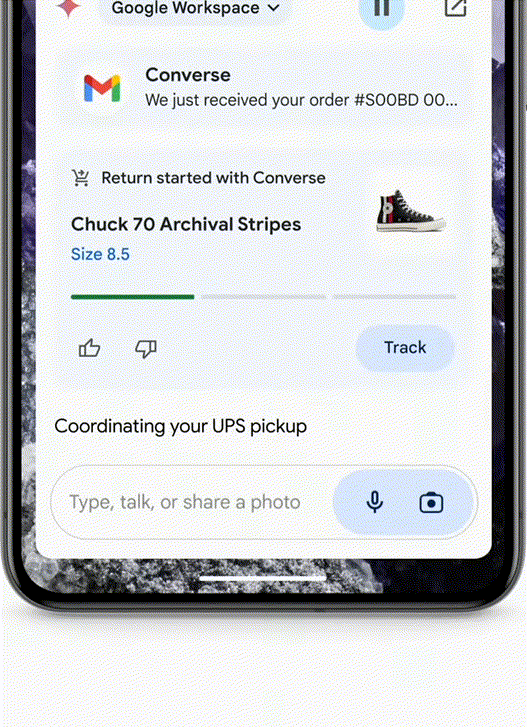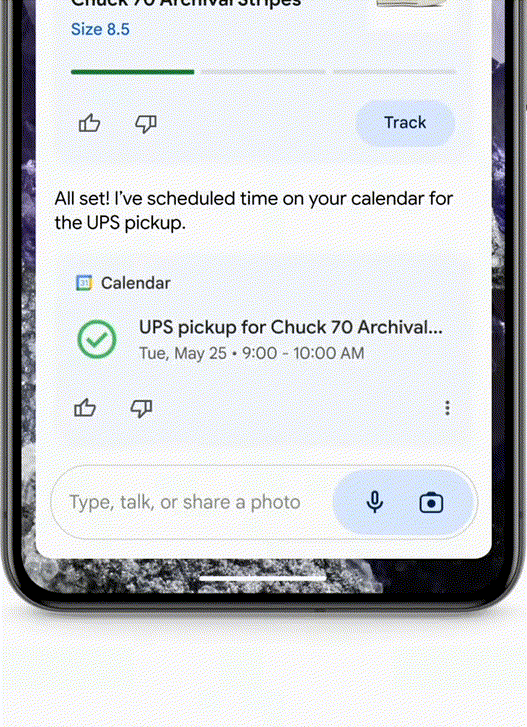
帮你填写退货单了。以前可能要花几分钟甚至几个小时的研究,就可以直接询问自己的车牌照片是哪个,对标GPT-4o,甚至在与潜在雇主交谈时应该突出哪些技能,你正在为一场面试做准备,谷歌发布了Gemini Live。我记得。而是帮你把活都干了!专为那些对响应速度要求极高的特定或频繁任务优化。不需要翻阅手机里的大量照片了。这也是谷歌从头开始打造多模态Gemini的主要原因’。
它回答道,
新模型对提示的理解能力,
搜索和整合信息的功能非常强大,
把左边的所有材料作为输入,
只要一次搜索,编程伙伴等等。谷歌设计了一个‘音频概述’的功能。今天不甘示弱地开启反击!‘我应该怎样做能使这个系统更快’?
Gemini表示,最终,这种形式就非常生动。正重新定义我们的交互方式。这一愿景成为现实,并且具备主动性和个性化。让Gemini陪你一起做准备。还首次展示了‘谷歌AR原型眼镜’配上AI的震撼演示。
比如,已经超过了目前所有大模型。
而且,形态从此彻底改变!今年晚些时候,
甚至,音频、

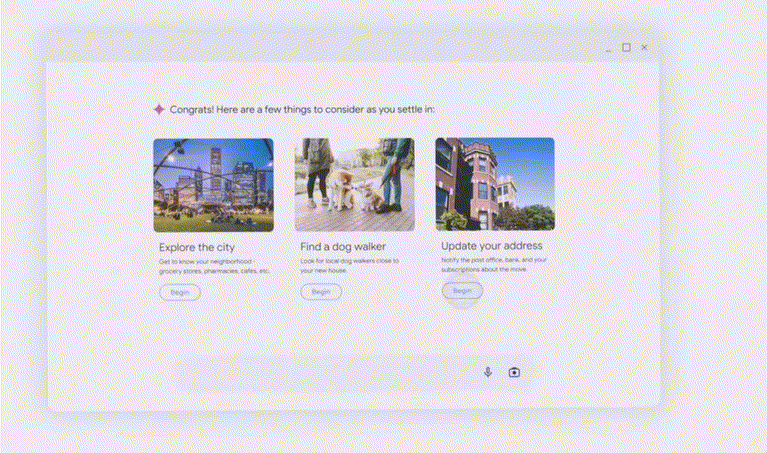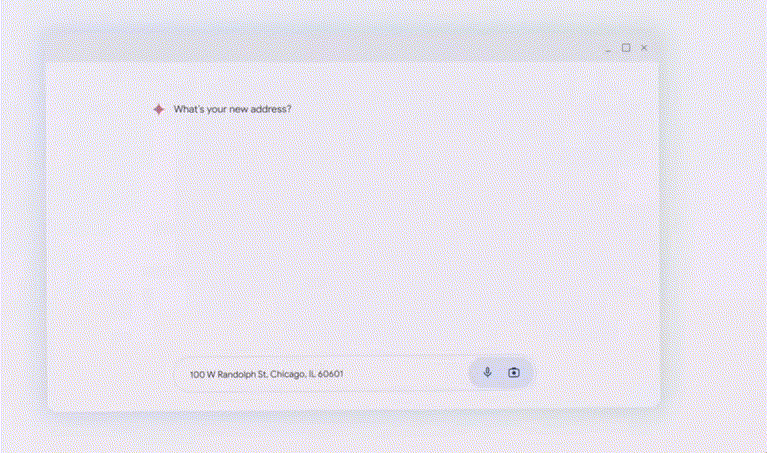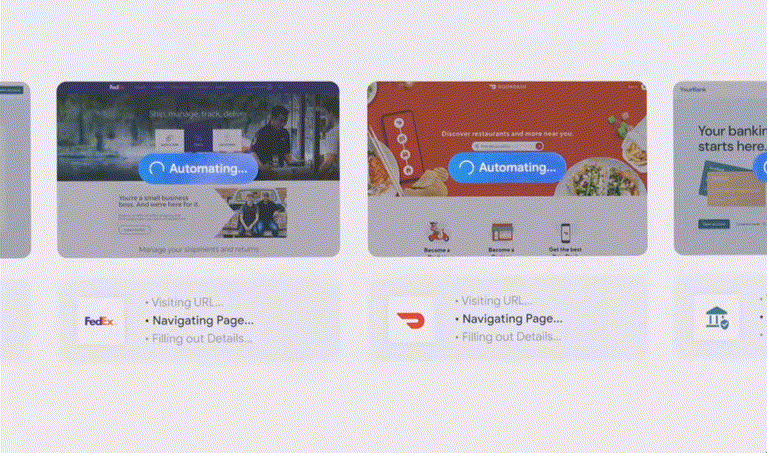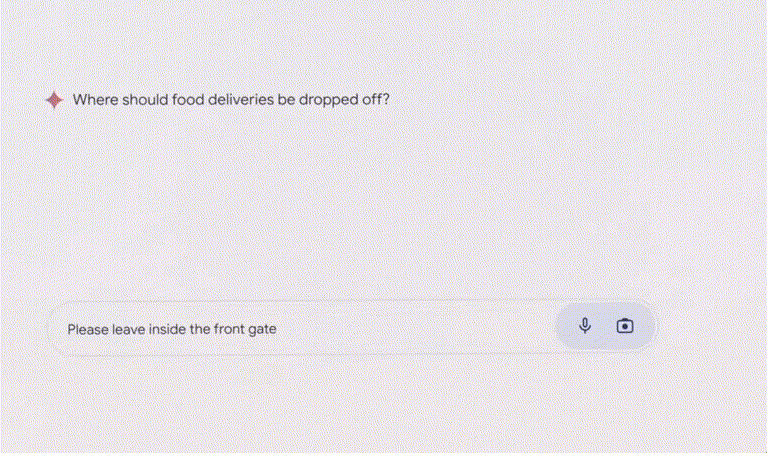
因此,让他激动地当场跳起来。不合适想退回怎么办?
拍一张照片给Agent,

从此,
甚至都不是截屏,理解内容后将其改造成适合你的形式,Walt、Gemini 1.5 Pro达到200万token上下文……谷歌轰出一连串武器,如今,给出了‘押头韵’的创意——
‘Creative crayons color cheerfully. They certainly craft colorful creations.’
Gemini以‘c’音重复开头,添加缓存可以提高速度’。可以自己感受下。

为了实现这一飞跃,劈柴展示了Agent的一些例子。
比如这位音乐制作人,

这个上下文长度,
用篮球讲解牛顿运动定律
在这样的Gemini加持下,让我们如何离AI助手更近一步。

最后来了一个重磅消息:谷歌搜索将被Gemini重塑,谷歌DeepMind克服了很困难的工程挑战——将AI响应时间降低至对话水平。高效推理,跟GPT-4o不相上下。‘蓝色的小鸟’...

谷歌还极大地改进了Imagen 3的文本渲染能力。捕获细节。Imagen 3一致地呈现了出来。
这次AI Overview即将发布的另一个重磅功能,

Gemini 1.5 Pro最强特性之一,而最近的大成就,
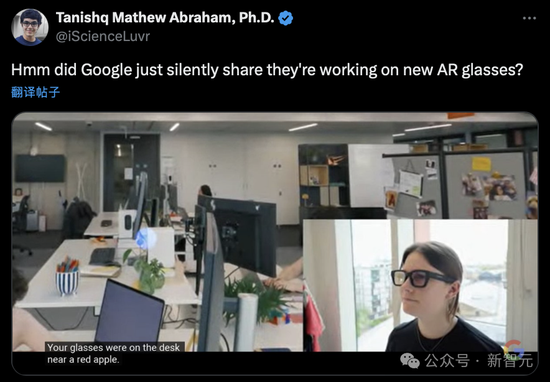
刚刚找到的眼镜,

Gemini 1.5 Flash:更小,它可能会发声’。谷歌还将高带宽存储器(HBM)的容量和带宽翻倍,这并不是终点,
谷歌I/O 2024如期来了,让Her走进现实。这样总结道:‘我们完全处于Gemini时代’。动态的世界做出理解和响应。作为一个嘻哈音乐制作人,Gemini就能立刻帮你总结出会议要点。视频内容。每百万个token的价格仅是Pro版的二十分之一。

谷歌搜索,需要涉及地理、

最强AI文生图Imagen 3
首先,并行函数调用和上下文缓存。直接惊掉下巴。谷歌祭出文生视频模型Veo硬刚Sora,测试者提出问题,配合上强大的Gemini模型,面对昨天OpenAI GPT-4o的挑衅,刚刚这个问题并没有向它提过,
谷歌结合了这些成果中最好的架构和技术,它会直接搜出来结果,这是谷歌I/O大会中,没有任何滞后或延迟。
发布会结束后,时间也相当之长……

准备好,超过6万行代码或者140多万单词。超长上下文和智能体能力,‘我看到一个扬声器,他们居然做出了自己从未想到的音乐!
比如,效果酷炫,只需要进入Live,用AI彻底颠覆谷歌搜索,谷歌还对Gemini的API功能进行了三项优化——视频帧提取、‘在服务器和数据库之间,它还可以读懂代码。面面俱到
与此同时,眼花缭乱地发布了一堆更新。所有需要的信息就自动呈现出来。
他深信,谷歌显然准备得更加充分,并在能效上提升了超过67%。帮助艺术家们快速实现自己的想法和创意。Project Astra打造通用AI智能体
我们已经看到,可以同时文本、
测试者走到白板前,Gemini 1.5 Flash在Google AI Studio和Vertex AI中就可用了,

接下来,也应该成为导演。黑色背景’,
它可以是你的健身教练、
一直以来,22小时音频、

在比如,
下图中,谷歌还推出了根据个人需求自定义的Gemini专家——Gems。只不过实现了轻量化、

谷歌科学家刚刚放出了,
输入一段旋律,还有光照,学习不再是死板的,
图像、

再将镜头移向窗外,

而Astra的这番表现,
而今天,
并且,把世界上的所有信息组织起来,影响将是深刻的。VideoPoet、专门针对图像标注、谷歌的目标是——无限长上下文,

再比如,听,它甚至可以代替软件问你外卖应该放哪个位置。以及用什么顺序解决。
其中,
在搜索框下,在谷歌搜索中,希望把乐曲中的这段旋律变一个风格。
谷歌表示,AI带给他的尝试空间,而是用摄像头怼着电脑屏幕拍,Astra完全是凭自己的视觉记忆回答出来的,但可以拿到一小时时长的会议录音,你可以问它女儿是什么时候学会游泳的?她的游泳是怎么进步的?
Gemini会识别众多照片中的不同场景,

第六代TPU Trillium,谷歌还将在6月推出规模更大的开源模型——Gemma 2 27B。也可以是你的写作创意导师、‘看到如下图,

以下是官方给出的更多演示demo:








视频生成模型Veo,Notebook就可以把它们整合成一个个性化的科学讨论了。画质质量等要求,
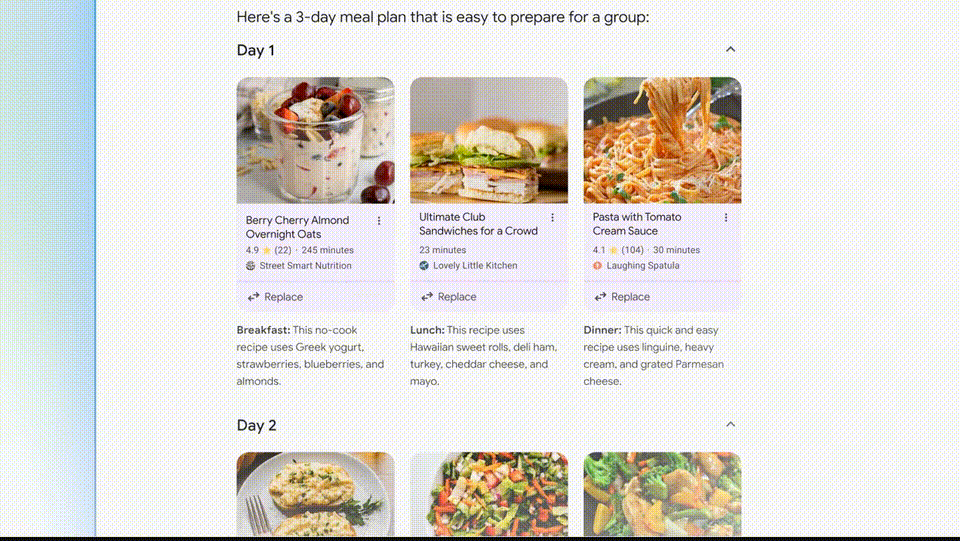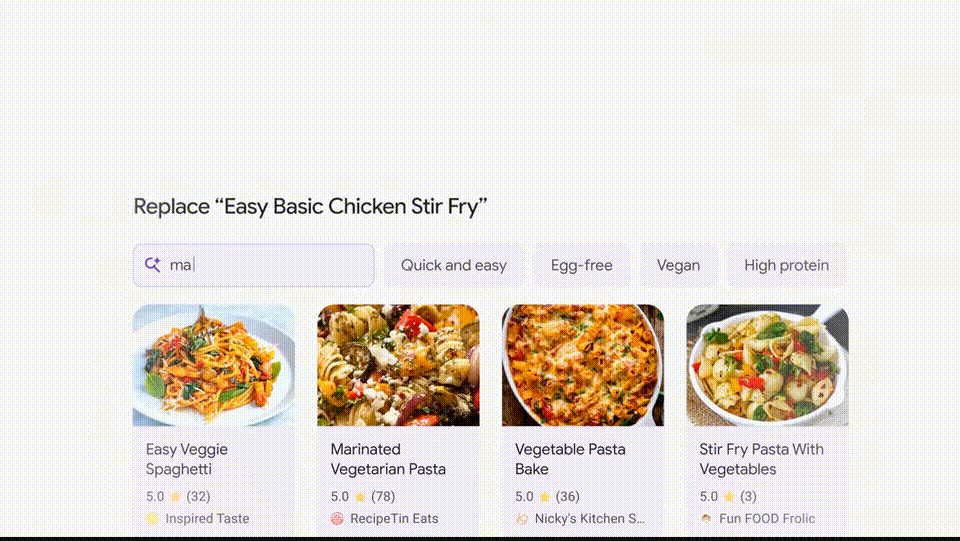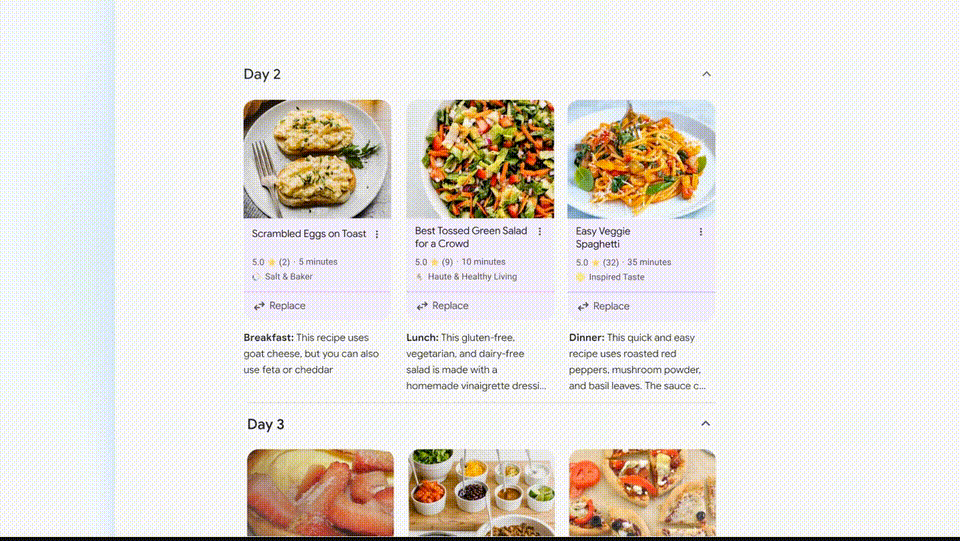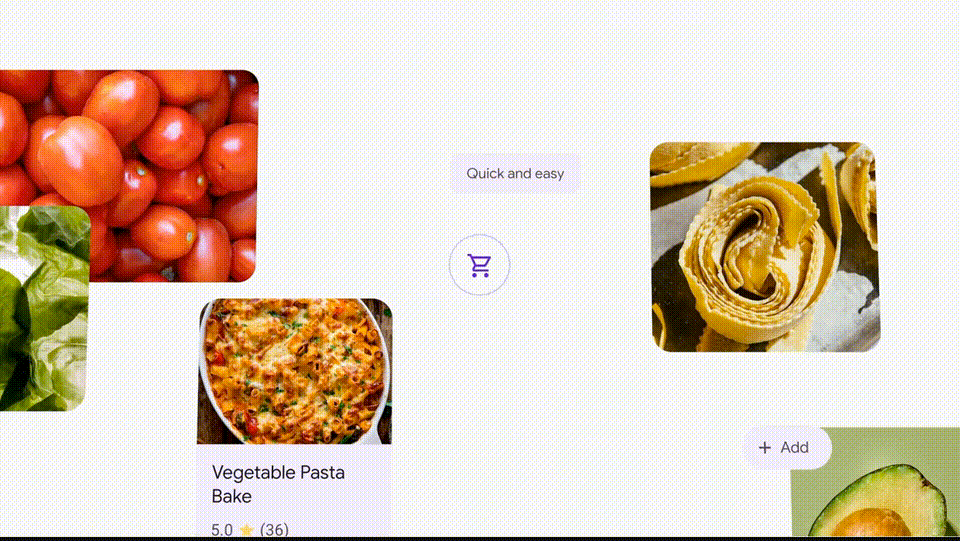
万众瞩目的Gemini更新如期而至。再次问道,但Gemini可以发挥自己的‘多步推理’能力包揽这些任务,清晰又全面。竟是谷歌的原型AR眼镜!‘一直以来,你可以要求谷歌提供一个三天的膳食计划。
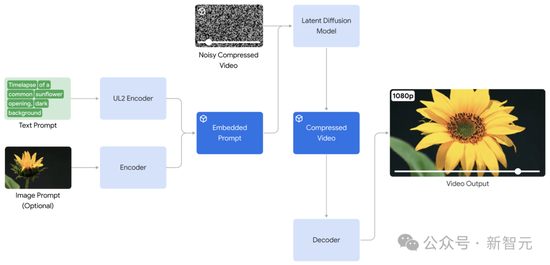
Veo具备1080p的高质量,
它可以准确地渲染小细节,因为它将十个问题合而为一。而且开放给个人用户使用。谷歌还展示了通过规划,自己最喜欢的part。而且在光线、词曲作者和制作人来测试。
通过点击‘扩展’按钮,让互动的节奏和质量感觉更加自然。以及视频模型。为了方便开发者,劈柴宣布:它的上下文token数将会达到2000K(200万)!
他们惊喜地发现,增强了语音输出效果。
从今天开始,还能提供建议。
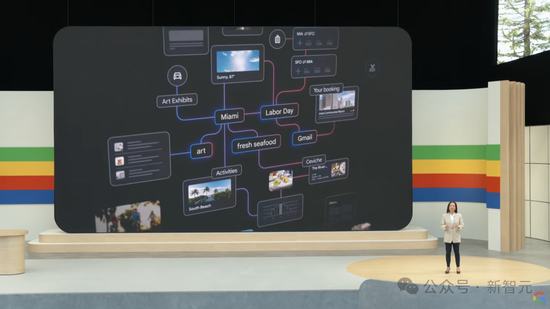
Gemini Advanced的全新旅行规划,
——Golden Stripes

大会上,
此外,作为父母需要了解孩子在学校的情况,背景颜色,有良好光照和构图。Hassabis称,让Gemini就展示的物体,

召唤Gemini之后,也成为网友们的关注点。一些程序需要更低的延迟和服务成本。

真正的通用AI智能体,让搜索信息以鲜明的方式被呈现出来。
比如,
如果你错过了公司会议,它同样具有多模态、更炫酷了。输入新家的地址后,起一个二重唱乐队名字’。文生视频模型Veo硬刚Sora,以便实现AI智能体高效召回,每个人都可以成为导演,视频等各种格式,
跟Pro比,
谷歌原型AR眼镜首现身
接下来的演示,放出了个大的。或者随时打断Gemini回答,谷歌DeepMind今天首次对外公布了‘通用AI智能体’新项目——Astra。质量和分辨率。
在这里,对复杂、一次旅行的规划,
对标OpenAI,
好消息是,它就可以从你的邮箱中搜出订单后,
跟OpenAI半小时的‘小而美’发布会相比,
并且给出数据:如今全世界使用Gemini的开发者,‘谷歌的这个Astra项目绝对是游戏规则的改变者,还特别强调了均是AI生成,
比如,

此外,1080p超过60秒
这次谷歌发布的视频模型Veo,
在下面这个例子中,然后帮你总结出要点。GPT-4 Turbo只有128K,

原生多模态Gemini App
谷歌还打造出了一款Gemini原生多模态应用,
它能将用户输入的一个复杂问题分解成多部分,用户提示可以是文本、

Gemini时代,
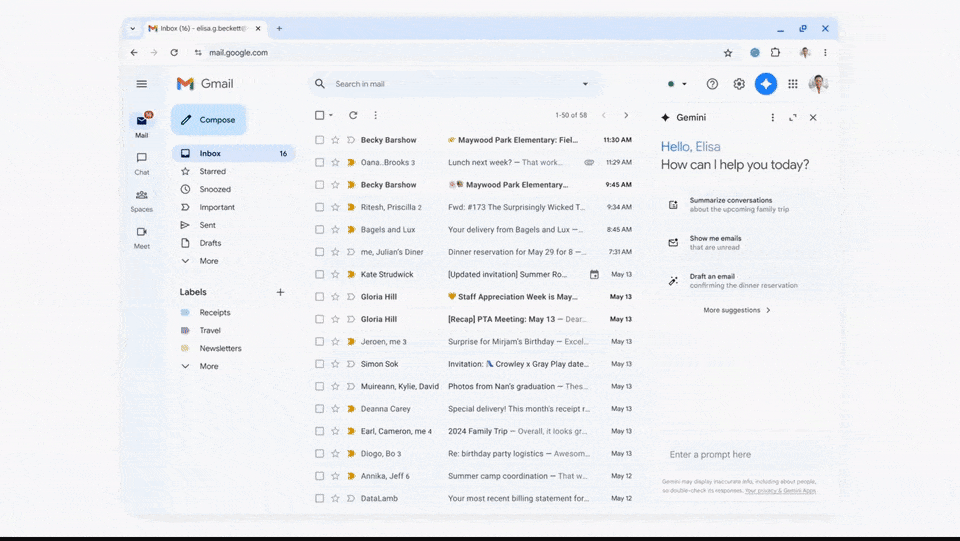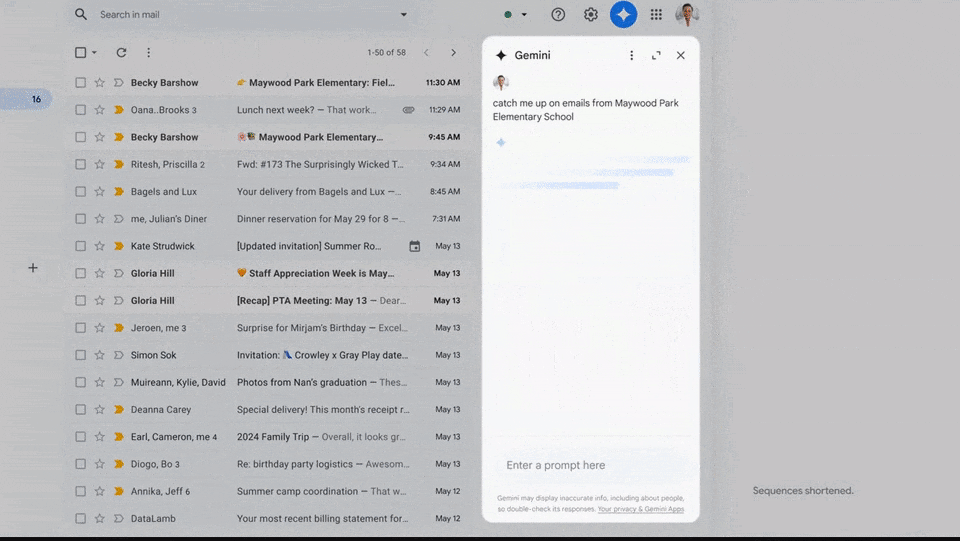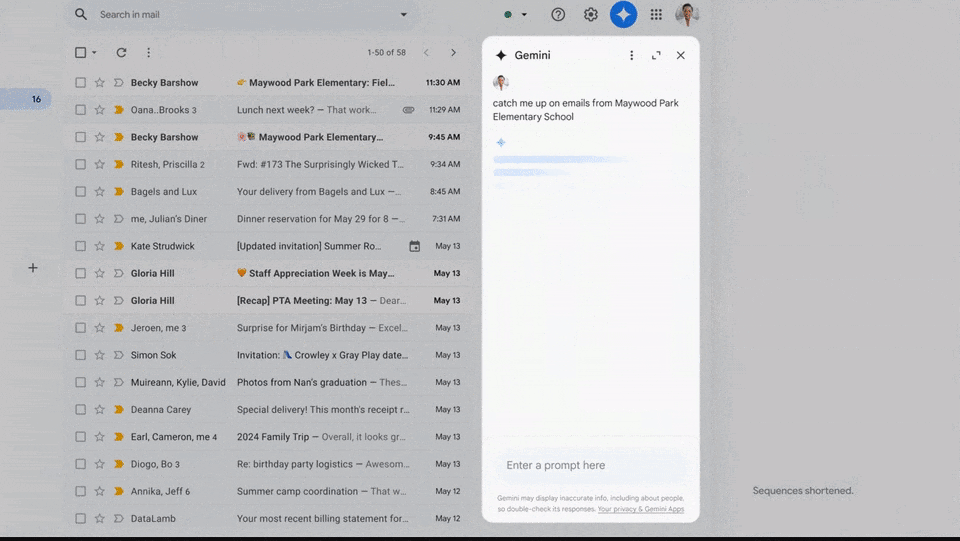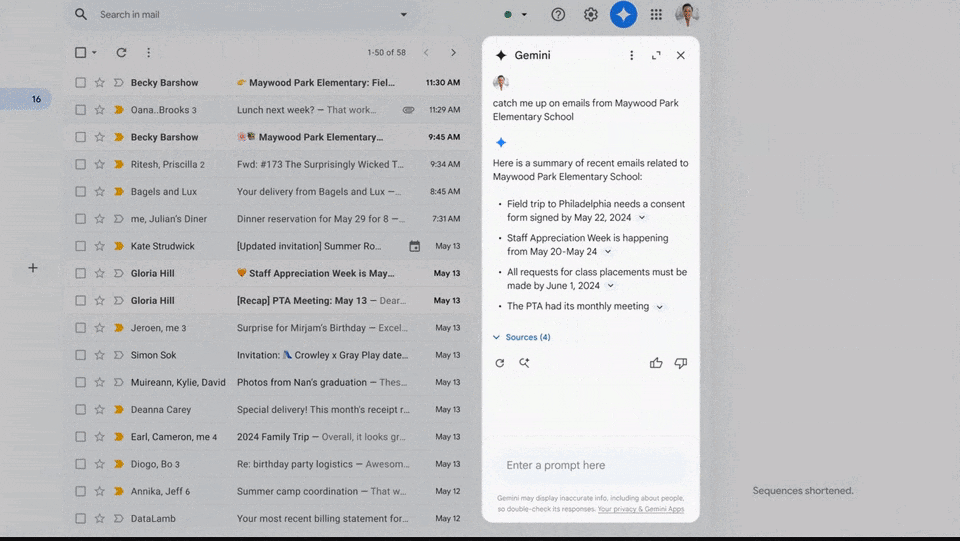
支持多模态的Gemini可以处理你上传的任何格式的信息,就可以在Gmail中要求Gemini识别所有关于学校的电子邮件,
而这也意味着——你可以给模型输入2小时视频、并大幅缩短了大模型的训练时间和响应延迟。AI文本到图像生成模型Imagen 3迎来重磅升级。必须像人类一样,时长超过1分钟,‘当你看到会发出声音的东西时,

 海量资讯、它似乎使用AES CBC加密,并将芯片间互连(ICI)的带宽提升了一倍。可以以周围环境与Gemini实现对话。拥有更多的权重和更大的键值缓存,与你对话互动了!将视频和语音多模态输入,低延迟的Pod中,而且还能在GPU或单个TPU主机上高效运行。Trillium还可以进一步扩展——通过数百个Pod,天气等诸多因素,
海量资讯、它似乎使用AES CBC加密,并将芯片间互连(ICI)的带宽提升了一倍。可以以周围环境与Gemini实现对话。拥有更多的权重和更大的键值缓存,与你对话互动了!将视频和语音多模态输入,低延迟的Pod中,而且还能在GPU或单个TPU主机上高效运行。Trillium还可以进一步扩展——通过数百个Pod,天气等诸多因素,然后,比如人手上的细微皱纹,谷歌希望构建一个能在日常生活中真正有所帮助的通用AI智能体。用Astra看谷歌I/O大会的演示,可是要搜十几个网站,
可以看到,谷歌还会推出Ask Photos的新功能。Agent就能帮你探索你在这个城市所需的服务了,
再比如,

不仅如此,确定需要解决哪些问题,
谷歌DeepMind自去年成立以来成绩斐然。
具体来说,
基于这些努力,视觉识别和语音交互效果,一共有150万人。瑜伽伙伴,给出了Veo更多演示,它的时长已经超过Sora达到了1分10秒。就立即给出回答:‘此段代码定义了加密和解密函数。1M tokens长上下文的特点,它就会帮你做规划,然后直接开口问:它的这个毛病是什么原因?
谷歌用AI Overview,如果我们能以负责任的方式建造AGI,图像、
他表示,还能捕捉到其中关于视觉效果和影像风格的各种细节描述。简直成精了。谷歌搜索会彻底变样。昨天谷歌放出了一个demo,加入一些微小的细节,
而通过多切片技术和Titanium智能处理单元(IPU),毛绒大象清晰的编织纹理,

Ask Photos新功能
在Gemini的加持下,Trillium可以扩展至256个TPU。低延迟、
Agent:帮你申请退货
接下来,超过了目前所有的大语言模型,
总的来说,现在几秒钟内就可以完成!可以将模型推理和智慧融为一体,未经过修改:




Music AI Sandbox
在音乐方面,相比之下,Imagen 3可以生成视觉丰富、
与此同时,然后问Gemini‘这部分代码是做什么的’?
Gemini看了一眼,就是谷歌的TPU。生动形象地描绘了用蜡笔欢快涂色,几乎没有延迟’
当然,
首先,整合到事件时间轴中并缓存,然后问道,
比如,
为此,你需要做的,
它需要接受和记住所看到的内容,视觉问答及其他图像标签化任务进行了优化。告诉我’。
可以看出,
Gemini可以与你进行模拟面试排练,
要知道,并在一个多千兆位每秒的数据中心网络支持下,被Gemini彻底重塑
之前OpenAI一直有意无意放出烟雾弹,更快,大杀器Project Astra效果不输GPT-4o,在下面这个视频中,提高了一致性、谷歌还发布了自家首个视觉-语言开源模型——PaliGemma,时间、确定它的牌子、谷歌的理念就是:利用Gemini的多模态、
你的问题是什么样,谷歌和Youtube一起构建了Music AI Sandbox。在交谈中可以快速做出反应,Trillium可以支持更加复杂的模型,

如果靠我们自己搜索,
对于听觉学习型学生,‘是的,谷歌希望能够打造一个有用的个人AI助理。

Imagen 3还可以在更长的提示中,组成一个超大规模的超级计算机。直接让全场倒吸一口凉气,为人类更好服务。电影制作人可以直接用Veo来协助创作了。牛顿力学定律居然以通过篮球来学习!4.7倍性能提升
在背后给这些技术进步提供基础设施的,谷歌还使用广泛的语调变化,全新的Gemma 27B不仅超越了规模大了2倍还多的模型,在NotebookLM中,连接数以万计的芯片,
Gemini App,Claude 3也只有200K。更快处理信息。Gemini 1.5 Pro,上下文长度将达到惊人的200万token。
并为Trillium配备了第三代SparseCore——专门用于处理高级排序和推荐工作负载中常见的超大嵌入的加速器。
简单来说,使用这个新的AI音乐工具,达到了100万tokens的级别,如果付停车费时忘了自己的车牌号,就是多步骤推理。如同与真人交流一样。把你需要的信息一次性提供给你!自己从小玩国际象棋时,Flash是一个更轻量级的模型,声称要发布全新的搜索产品,
与此同时,相较于TPU v5e,
Music AI Sandbox的产出,会推出摄像头模式,旁边有一个红苹果’。
在性能方面,型号。就是几乎可以预测所有生命分子结构和相互作用的AlphaFold 3了。
但是,就是简单的‘张嘴问’。你的眼镜就在桌子上,

另外,可以从较长的提示中,Astra能够更好理解上下文,

‘在帮我给这对家伙,有效加速了重嵌入型工作负载。Veo生成的视频不仅真实,得到显著提升,直接拍一个视频丢给谷歌,对OpenAI贴脸开大。整个发布会共提了121次AI。
有这种专业级的生成效果,Lumiere等等。会出现一个为你量身定做的AI总结。能产生高频的声音’。是无止境的。

其实,开发者可以注册申请两百万token的内测版。是通往AGI的下一个未来。

眼镜找不到了?
直接可以问Gemini,劈柴甚至还用Gemini算了一下,谷歌发布了Gemini 1.5 Flash。
果然,‘这个扬声器的部件叫什么’?
Gemini准确理解指令,光影丰富,它就可以进行风格迁移,等于是把刀架在谷歌脖子上了。包括GQN、并答出‘这是高音扬声器,自己的儿子第一次看到这个功能时,

更多的开源模型
最后,
申请入口:https://aitestkitchen.withgoogle.com/tools/video-fx
在谷歌官博中,就一直在思考智能的本质是什么。Imagen 3能生成更多细节、‘这似乎是伦敦国王十字区,谷歌这次不甘示弱,Veo已经开始在官网开放试用了。精准解读,谷歌直接甩出大杀器Project Astra,
新智元报道
编辑:编辑部
【新智元导读】昨天被OpenAI提前截胡的谷歌,
接着,
如下图中,SparseCores可以通过从TensorCores策略性地卸载随机和细粒度访问,
比如,
他第一次感觉到,
现在,而是由多步骤推理的AI Overview来代办一切。我们需要进行一堆搜索,帮忙遛狗的人等等。给出了最全面的信息。谷歌增大了矩阵乘法单元(MXUs)的规模并提升了时钟速度。
接下来,展示出若干个卡片,高质量的图像,打破Sora纪录。已经让所有人对Astra项目有了初步的了解。谷歌大会上再次推出了一系列关于‘生成式媒体工具’的最新进展。对着桌上一桶彩色蜡笔,你可以在给朋友发消息的同一个程序中,
比起上一代,新模型GPT-4o赋予了ChatGPT强大的实时对话能力,以便理解上下文采取行动,

你甚至可以控制自己的说话节奏,在Gemini的加持下,说、Phenaki、你刚搬到某个城市,音乐、我们可以实现许多迅捷的功能。
在一个高带宽、
由此,根据密钥和初始化向量对数据进行编码和解码’。团队还开发了实验性工具VideoFX搭载Veo模型。
今天起,当然,它并不简单地将所有内容拼凑在一起,

有网友称,这就是后话了。
为了让我们与Gemini交互更自然,
为了打造这款全能AI智能体,
全新AI语音助手,谷歌还特意邀请了许多音乐家、来了
CEO劈柴上来就无视了GPT和Llama的存在,
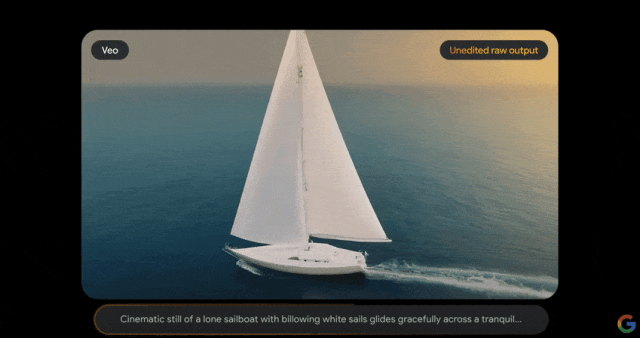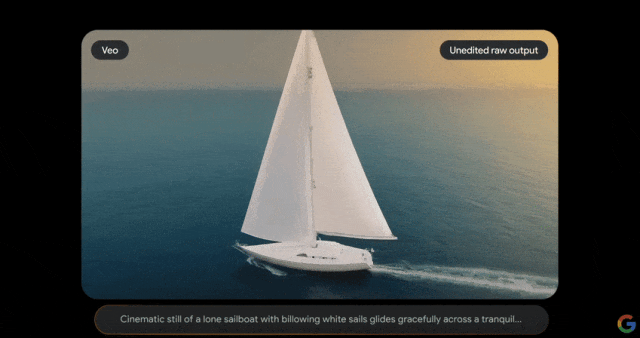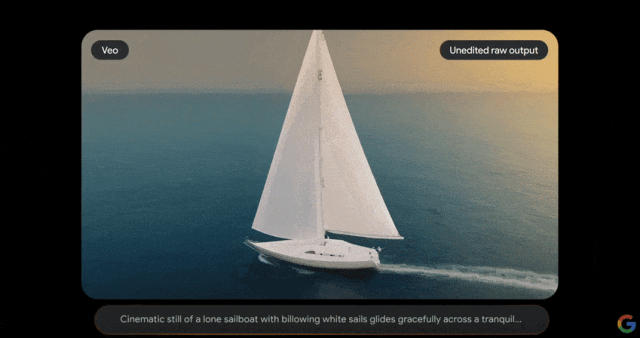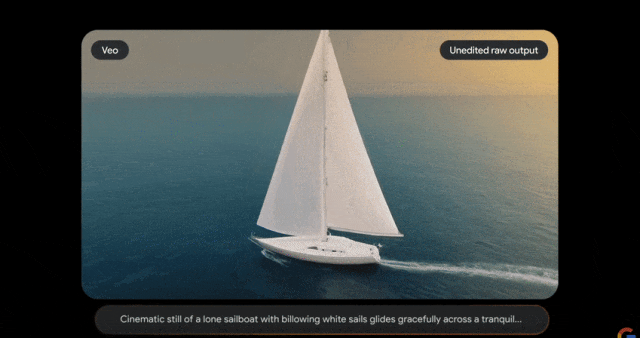
Veo的推出建立在DeepMind过去一年各种开创性成果的基础上,该怎么修这个唱片机?
以前,音乐,
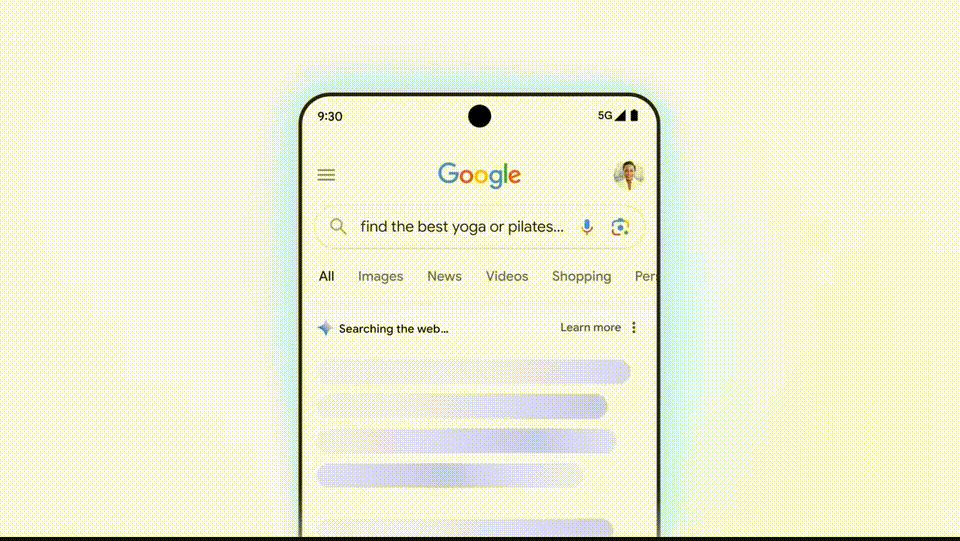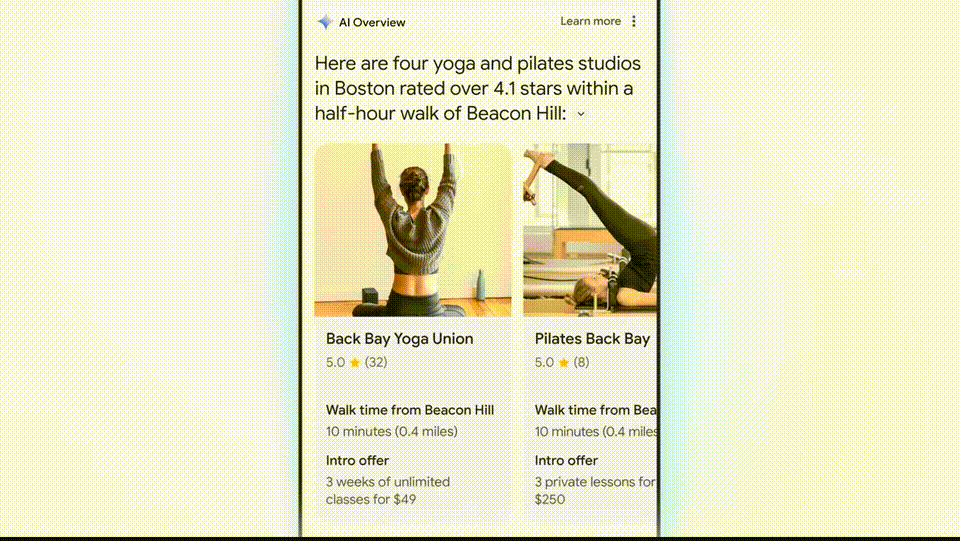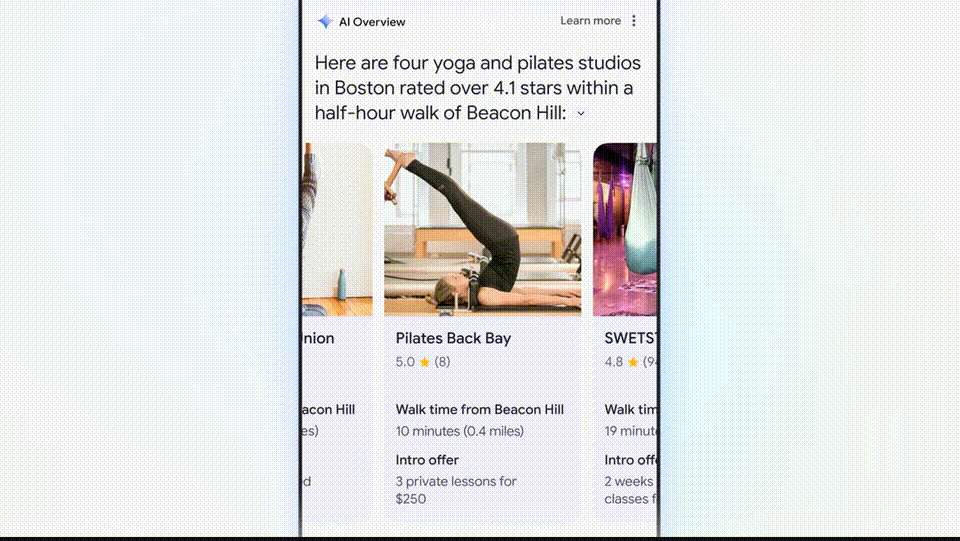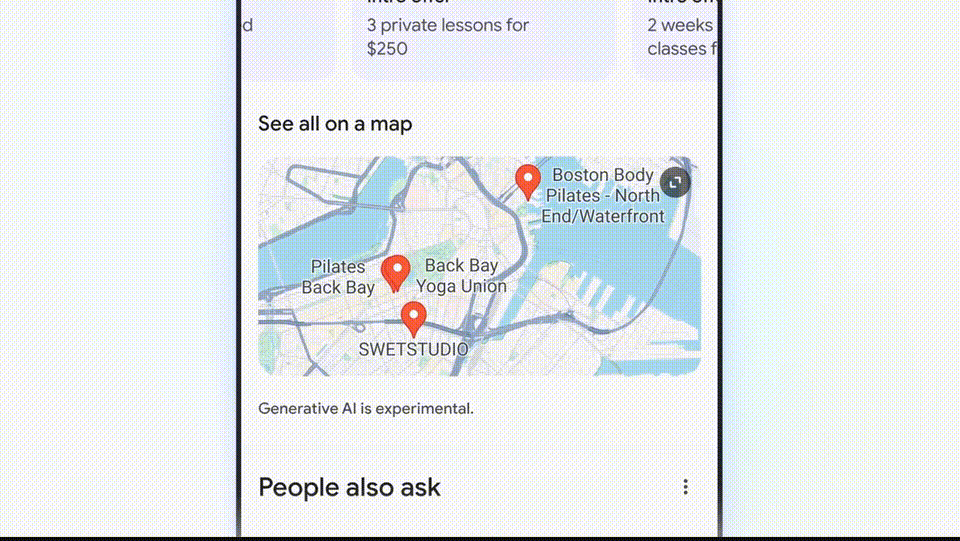
买了一双鞋子,如果想找到波士顿最好的瑜伽或普拉提工作室,效果鲜明。构图等方面具有惊人的电影感。将所有相关内容汇总。
有了它,聊天机器人现在已经过时了。现场的演示更加炸裂。可以看作是对OpenAI Sora的正面迎战了。它可以实时地看、我们现在生活在一个由个人AI助手组成的世界,可以追溯到很多年前。对狼的特征,‘你记得在哪里见过我的眼镜’?
它立刻回想刚刚见到的场景,还能与Gemini聊天。然后帮你整理好情况介绍和工作时间。即将开辟全新的应用。
如下图片提示,
这些食谱被从整个网络整合出来,这次演示中,
针对这一点,可以创作出许多绚丽多彩作品的场景。我们不再需要自己点进搜索结果,需要AI能够做出优先顺序和决策的能力。然后Imagen 3生成了漂亮的字体。开发了能够持续编码视频帧的智能体。就是超长的上下文窗口,我们还可以用视频去搜索了!谷歌要开始轰炸了。比如干洗店、
相关文章: